Processor Stages
Cube Processor Stage
This stage allows you to perform lookups of key-value pairs that are stored in a cube, and pass the lookup values to fields. Use Cube Processor when you want to enrich your records, at runtime, with additional data.
To add a Cube Processor stage to your pipeline
- With your pipeline in Edit mode, filter out the Stage library, by selecting Processors, to display only the processors stages.
- In the stage search box, start to type
cubeand select the Cube Processor stage from the filtered list. The Cube Processor stage is added to your pipeline.
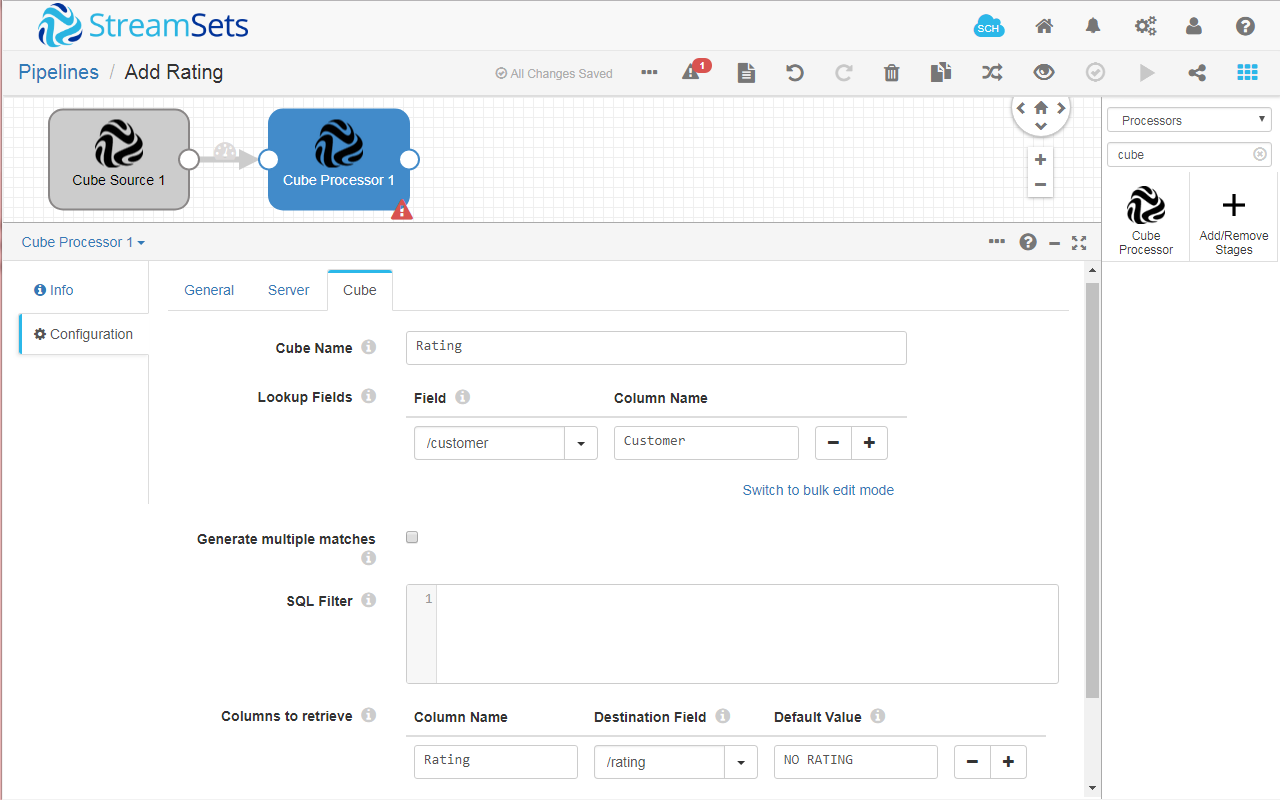
Fig. 25: The Cube Processor processor configuration.
Notes
- You can select multiple lookup fields. In this case, the keys will match conjunctively.
- You can select multiple additional columns to enrich data.
- If you don’t provide a lookup column name, the field name of the existing stream is used.
- If you don’t provide a destination field, the additional data is stored in a destination field with the same name as the lookup column, provided that it exists.
- If you select Fill with default values (default option), you can provide a default value in the Default Value field of the Columns to retrieve section. This will apply that value to all non-matching records from the lookup cube.
- The Generate multiple matches option allows you to select the matching records of a particular key. If you enable the option, all the matching records are added to the stream. Otherwise, only the first matching record is kept.