Origin Stages
Cube Source Stage
In the Exposure-per-Rating App Tutorial you are introduced to the Cube Source Stage. This stage allows you to use one or more existing cubes as origins in your Data Manipulation Tool pipelines.
To add a Cube Source stage to your pipeline
- With your pipeline in Edit mode, filter out the Stage library by selecting Origins, to display only the origin stages.
- In the stage search box, start to type
cubeand select the Cube Source stage from the filtered list. The Cube Source stage is added to your pipeline.
To use the Cube Source stage with a single cube
- Click the Cube Source stage from your pipeline.
- In the Configuration section of the stage, click the Cube tab.
- In Cubes > Cube name enter the name of the cube that you want to source data from.
- (Optional) In Column names and field names you can select and rename what columns you want to use from the source cube. Click and add pairs following the pattern:
<source_column_name>:/<destination_field_name>
When you use this feature, the columns that you don’t add in this list are not retrieved from the source cube.
Note the mandatory slash -
/that prepends the name of the destination field.
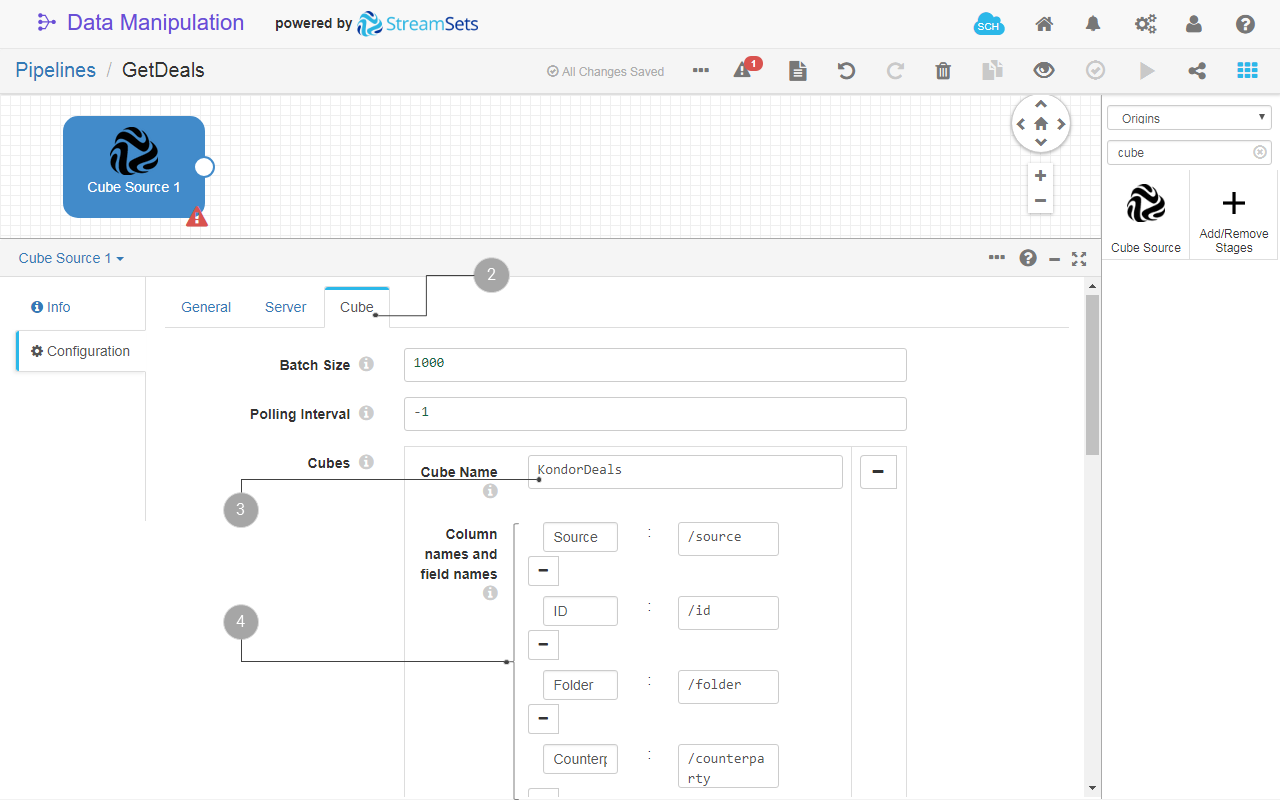
Fig. 20: The Cube Source origin configuration with single cube import.
To use the Cube Source stage with multiple cubes
When you use multiple cubes, the stage allows you to combine them like you would do a union in relational databases. To use multiple cubes:
- At step 4 in the previous procedure, click to add the configuration for an additional cube.
- Enter the Cube Name.
- (Optional) Fill in Column names and field names list, as you would do with a single cube source.
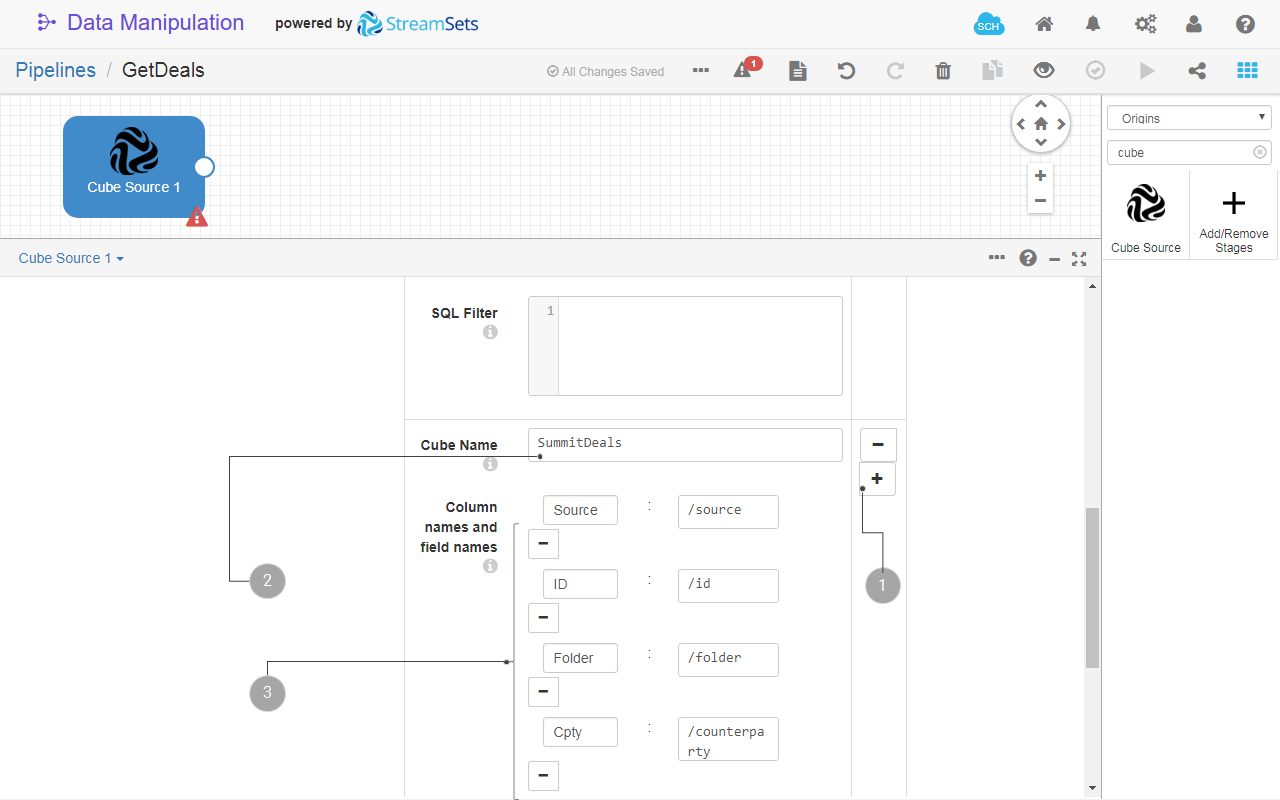
Fig. 21: The Cube Source origin configuration with multiple cubes import.
Notes:
- If you run the pipeline in Preview mode, you see how the data is combined in the table view. For example, in fig. 22 the data is marked as follows:
- The data loaded from the cube
KondorDeals. - The data loaded from the cube
SummitDeals.
- The data loaded from the cube
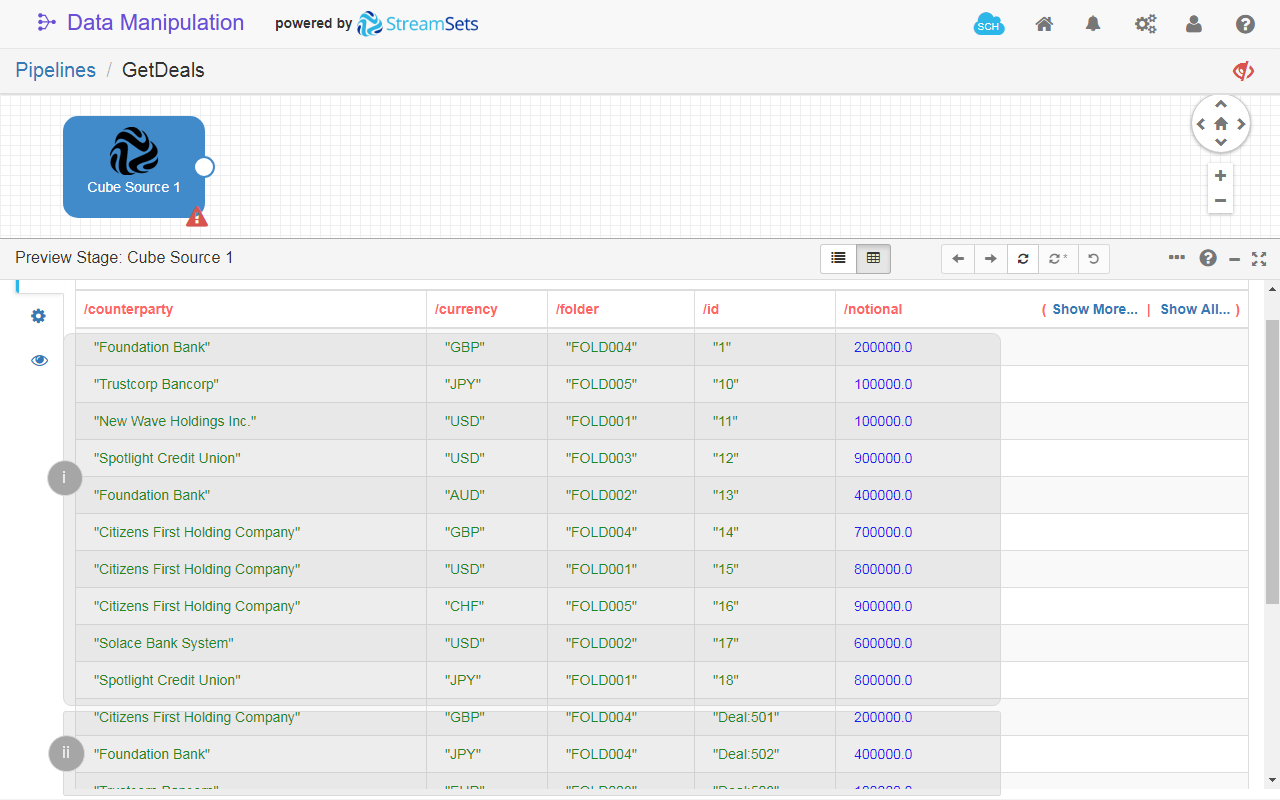
Fig. 22: The table view of the Cube Source 1 in pipeline preview mode. The data is loaded from two cubes that store deals data from two core systems.
- For this example, the Column names and field names option was used to rewrite the names of the fields, as shown in fig. 23. This way, the data from columns that were named differently, such as
CounterpartyandCpty, is stored in the same field,/counterparty. Thus, this stage allows you to combine the data while enforcing consistency too.
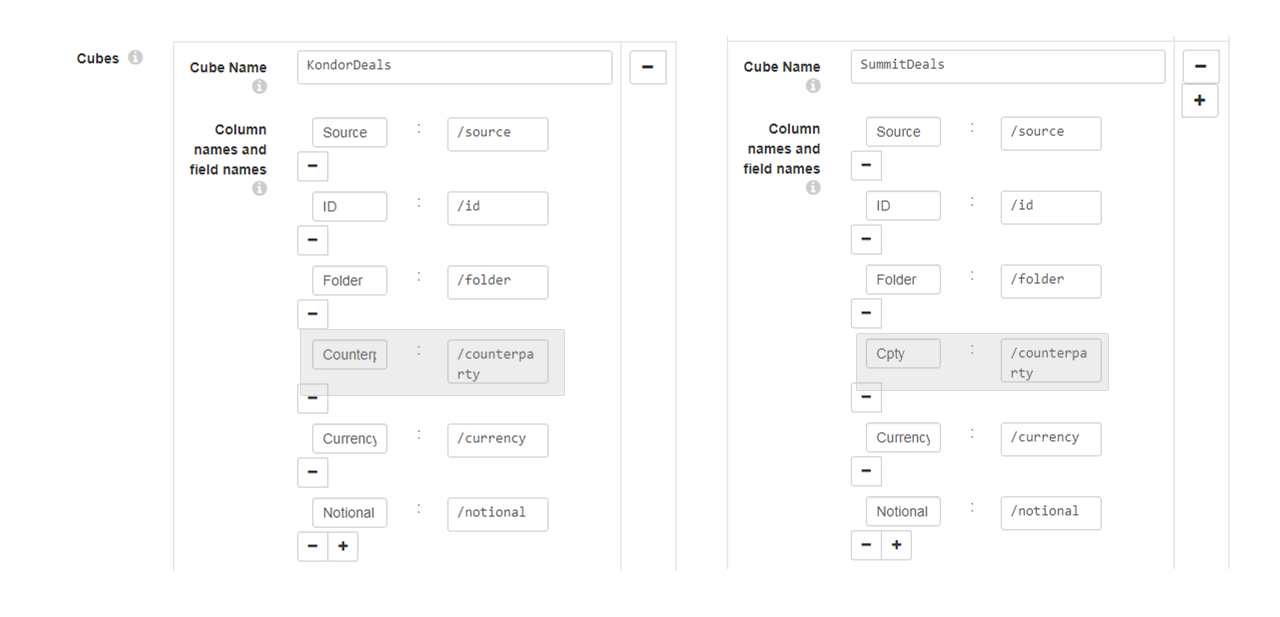
Fig. 23: The Column names and field names option used to rewrite the names of the fields, enforcing data consistency when combining data form two cubes.
- If any of the fields in the Column names and field names pair lists is named differently, the data is stored in separated fields.
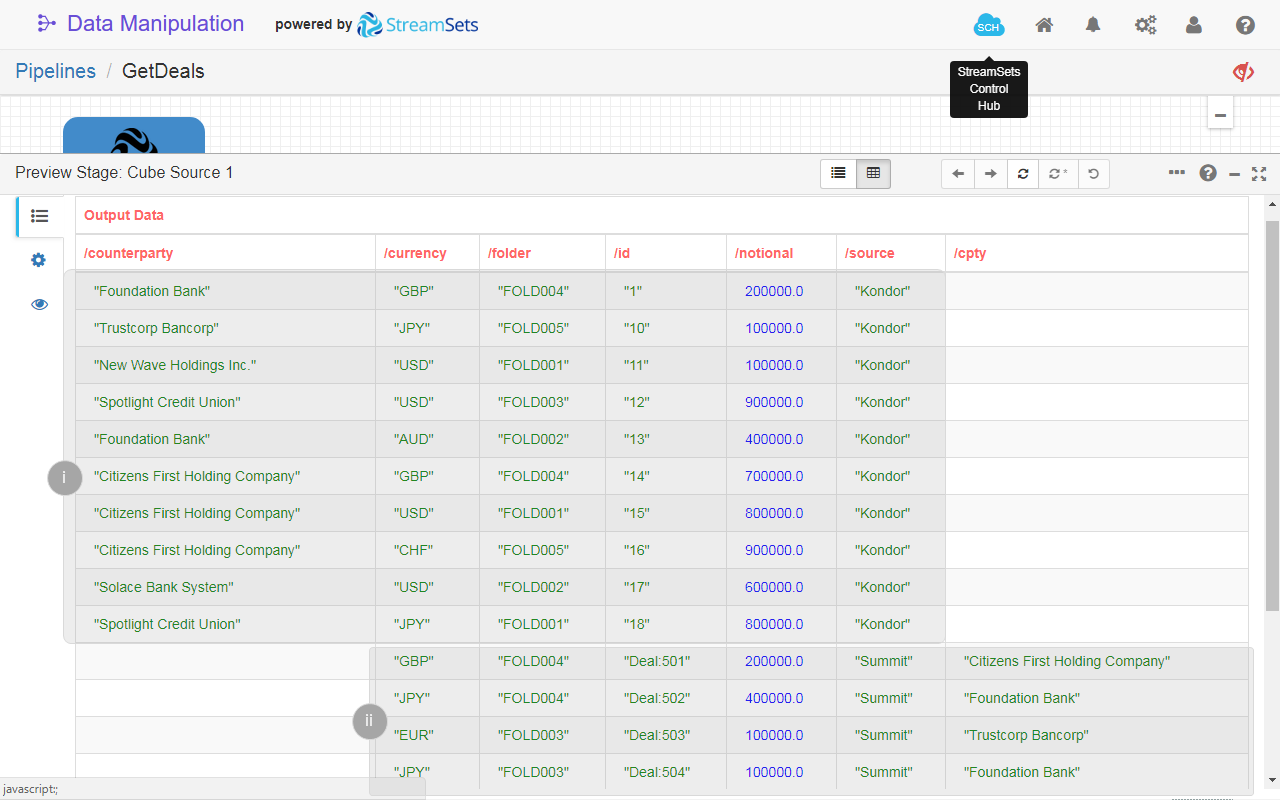
Fig. 24: The table view of the Cube Source 1 in pipeline preview mode. The data is loaded from two cubes that store deals data from two core systems. Note the different fields that store the same type of information: /counterparty and /cpty.
- If you don’t use Column names and field names pair list, all columns from all source cubes are kept in the destination data structure, with the same name. This is an enhancement of the RDBMS union , were the data structures that are combined with union must have the same number of columns and of the same type.
- The column name is case-sensitively interpreted. Therefore, if you have column names, such as:
Customerandcustomerin two cubes, both columns will be stored in the destination data structure.